
기록
day 0624 본문
뷰(View)
==> 실제 물리적으로는 존재하지 않는 가상의 논리적인 테이블을 말합니다.
- 자주사용하는 복잡한 sql을 view를 만들어 둠으로써
편리하게 사용할 수 있어요.
- 사용자 별로 접근 권한을 두고자 할 때에
View를 이용합니다.
-----------------------------------------------------------
create view 뷰이름 as select ~
연습) 이번달에 판매량이 가장 높은
상위 3권의 도서의 정보를 조회
- 판매정보는 orders에 있으니
orders테이블로 부터 이번달에 판매된 도서번호 별로
판매량을 조회, 판매량 순으로 내림차순 정렬
select bookid, count(*)
from orders
where
to_char(sysdate, 'yyyy/mm') =
to_char(orderdate, 'yyyy/mm')
group by bookid
order by count(*) desc;
select bookid
from (select bookid, count(*)
from orders
where
to_char(sysdate, 'yyyy/mm') =
to_char(orderdate, 'yyyy/mm')
group by bookid
order by count(*) desc)
where rownum <= 3;
select * from
book where
bookid in (select bookid
from (select bookid, count(*)
from orders
where
to_char(sysdate, 'yyyy/mm') =
to_char(orderdate, 'yyyy/mm')
group by bookid
order by count(*) desc)
where rownum <= 3);
create view top3
as
select * from
book where
bookid in (select bookid
from (select bookid, count(*)
from orders
where
to_char(sysdate, 'yyyy/mm') =
to_char(orderdate, 'yyyy/mm')
group by bookid
order by count(*) desc)
where rownum <= 3);
SQL> select * from top3;
BOOKID BOOKNAME PRICE PUBLISHER
------ -------------------- -------- --------------------
14 재미있는 자바 34,000 삼성당
2 축구아는 여자 13,000 나무수
15 신나는 자바 34,000 삼성당
연습) 오늘날짜의 출판사별 총판매수량, 총판매금액을 조회하는
뷰를만들고 실행 해 봅니다.
select publisher,
count(orderid), sum(saleprice)
from orders o, book b
where o.bookid = b.bookid and
to_char(sysdate, 'yyyy/mm/dd') =
to_char(orderdate, 'yyyy/mm/dd')
group by publisher;
위의 sql을 view를 만들어 보겠습니다.
create or replace view today_sale
as
select publisher,
count(orderid) cnt, sum(saleprice) sum
from orders o, book b
where o.bookid = b.bookid and
to_char(sysdate, 'yyyy/mm/dd') =
to_char(orderdate, 'yyyy/mm/dd')
group by publisher;
==> count, sum등의
집계함수로 뷰를 만들때에는
애칭이 필요합니다.
연습) 뷰를 통해서 조건에 맞는 레코드만 조회하기
판매건수가 2건이상 인 것만 조회하기
SQL> select * from today_sale;
PUBLISHER CNT SUM
-------------------- ---------- ----------
굿스포츠 1 34000
나무수 2 68000
대한미디어 1 34000
삼성당 4 136000
SQL> select * from today_sale where cnt >= 2;
PUBLISHER CNT SUM
-------------------- ---------- ----------
나무수 2 68000
삼성당 4 136000
SQL> select publisher from today_sale where cnt >= 2;
PUBLISHER
--------------------
나무수
삼성당
연습) 도서명에 '축구'를 포함하고 있는 도서의 정보를 조회하는
뷰를 생성해 봅니다.
뷰이름은 vw_book이라고 합니다.
create view vw_book
as
select * from book
where bookname like '%축구%';
연습) '대한민국'에 거주하는 고객의 정보를 출력하는 뷰를 생성합니다.
vw_customer
create view vw_customer
as
select * from customer
where address like '대한민국%';
** View를 사용하는 목적
- 자주 사용하는 복잡한 sql 대신
- 보안유지상 사용별로 조회할 수 있는 칼럼을 제한
create user c##kim identified by kim;
grant connect, resource to c##kim;
연습) c##madang이 갖고 있는 테이블
emp 중에 c##kim에게
사원번호, 사원명, 부서번호, 이메일만
조회할 수 있는 권한을 부여하고 싶어요!
create or replace view vw_emp
as
select eno, ename, dno, email
from emp;
** 권한 부여
grant select on c##madang.vw_emp to c##kim;
** 권한 제거
revoke select on c##madang.vw_emp from c##kim;
c##kim 이 로그인하여 다음을 조회
SQL> select * from c##madang.vw_emp;
ENO ENAME DNO EMAIL
----- ---------- ----- ------------------------------
1000 변시우 10
1001 이동준 10 edj19877@gmail.com
1002 박성빈 10 goodstar7369@naver.com
1003 임유나 10 dladbsk674@naver.com
1004 홍석영 10 ghdtjrdud38@naver.conm
1005 최모래 20 principle950@naver.com
SQL> select * from c##madang.emp;
select * from c##madang.emp
*
1행에 오류:
ORA-00942: 테이블 또는 뷰가 존재하지 않습니다
================================================================
연습) 20번 부서에 근무하는
직원들의 사원번호, 이름, 직책, 입사일, 부서번호를
조회하는 뷰를생성
(vw_emp20)
create view vw_emp20
as
select eno, ename, job, hiredate, dno
from emp
where dno = 20;
궁금하다)
뷰를 통해서 추가, 수정, 삭제가 가능할까?
insert into vw_emp20
values(3000, '홍철수', '사원', sysdate, 20);
==> 추가가 가능합니다.
실제로는 뷰를 만들 때 사용한
emp테이블에 레코드가 추가되고
뷰의 속성 이외의 속성들이 null을 허용하거나 default값이 있어야지만 추가 할 수 있어요.
insert into vw_emp20
values(3001, '홍철식', '사원', sysdate, 30);
==> 뷰 생성시에 사용된
조건에 맞지 않는 레코드도
추가 됩니다.
==> 모테이블에 추가되고 뷰에는 조회가 되지 않습니다.
---------------------------------------------------------
뷰를 통해서 수정하기
update vw_emp20 set job = '과장'
where eno = 3000;
update vw_emp20 set dno = 30
where eno = 3000;
==> 뷰를 통해서 수정이 가능하다.
==> 뷰 생성시 사용한 조건과 다른값으로도 수정이 가능하다.
---------------------------------------------------------
delete vw_emp20 where eno=3001;
==> 뷰를 통해서 삭제가 가능하다.
==> 실제로는 뷰 생성시에 사용한 모테이블에서 삭제가 됩니다.
---------------------------------------------------------
뷰를 통해서
추가, 수정, 삭제가 가능하다.
실제로는 모테이블에 추가,수정,삭제가 일어난다.
또, 뷰 생성시의 조건과 맞지 않는 자료의 추가,수정이 가능하다.
-----------------------------------------------------
<< 뷰 삭제 하기 >>
drop view 뷰이름;
-----------------------------------------------------
** 뷰를 생성할 때 설정한
조건에 맞지 않는 레코드를 추가 할 수 없도록
조건에 맞지 않는 값으로 수정 할 수 없도록
뷰를 만들고 싶어요.
with check option
create view vw_emp20
as
select eno, ename, job, hiredate, dno
from emp
where dno = 20
with check option;
SQL> insert into vw_emp20 values(4000,'김유신', '사원', sysdate, 20);
1 개의 행이 만들어졌습니다.
SQL> insert into vw_emp20 values(4001,'유관순', '사원', sysdate, 30);
insert into vw_emp20 values(4001,'유관순', '사원', sysdate, 30)
*
1행에 오류:
ORA-01402: 뷰의 WITH CHECK OPTION의 조건에 위배 됩니다
SQL> update vw_emp20 set job = '과장' where eno = 4000;
1 행이 업데이트되었습니다.
SQL> update vw_emp20 set dno = 30 where eno = 4000;
update vw_emp20 set dno = 30 where eno = 4000
*
1행에 오류:
ORA-01402: 뷰의 WITH CHECK OPTION의 조건에 위배 됩니다
==================================================================================
** 조회(읽기) 만 가능한 뷰 생성
with read only
create view vw_emp20
as
select eno, ename, job, hiredate, dno
from emp
where dno = 20
with read only;
SQL> insert into vw_emp20 values(5000,'이순신', '사원', sysdate, 20);
insert into vw_emp20 values(5000,'이순신', '사원', sysdate, 20)
*
1행에 오류:
ORA-42399: 읽기 전용 뷰에서는 DML 작업을 수행할 수 없습니다.
SQL> update vw_emp20 set job = '사원' where eno =4000;
update vw_emp20 set job = '사원' where eno =4000
*
1행에 오류:
ORA-42399: 읽기 전용 뷰에서는 DML 작업을 수행할 수 없습니다.
SQL> delete vw_emp20 where eno=4000;
delete vw_emp20 where eno=4000
*
1행에 오류:
ORA-42399: 읽기 전용 뷰에서는 DML 작업을 수행할 수 없습니다.
==> 읽기 전용의 뷰에서는
조회만 가능하고
추가,수정,삭제는 할 수 없어요!
--------------------------------------------------
시스템 뷰
==> 오라클이 제공하는 미리 만들어 놓은 뷰를 말하며
"데이터 사전"이라고도 합니다.
user_objects
==> 사용자가 만든 객체의 정보를 갖고 있는 데이터 사전
user_tables
==> 사용자가 만든 테이블의 정보를 갖고 있는 데이터 사전
user_contraints
==> 사용자가 만든 모든 제약의 정보를 갖고 있는 데이터 사전
----------------------------------------------------------
내가 만든 어떤것이 이름이 잘 기억이 나질 않아요!
user_obejcts를 조회합니다.
user_objects는
오라클이 제공하는 뷰 입니다.
이것은 구조를 확인 해 보겠습니다.
desc user_objects;
QL> desc user_objects;
이름 널? 유형
----------------------------------------- -------- ----------------------------
OBJECT_NAME VARCHAR2(128)
SUBOBJECT_NAME VARCHAR2(128)
OBJECT_ID NUMBER
DATA_OBJECT_ID NUMBER
OBJECT_TYPE VARCHAR2(23)
CREATED DATE
LAST_DDL_TIME DATE
TIMESTAMP VARCHAR2(19)
STATUS VARCHAR2(7)
TEMPORARY VARCHAR2(1)
...
굉장히 많은 칼럼들로 구성되어 있습니다.
이 중에 object_name을 조회 해 보겠습니다.
select object_name from user_objects;
SYS_C008324
SYS_C008328
DETAIL
PRODUECT
SYS_C008330
SYS_C008422
극장
상영관
SYS_C008425
고객
SYS_C008427
예약
SYS_C008428
TOP3
TODAY_SALE
VW_BOOK
VW_CUSTOMER
VW_EMP
VW_EMP20
조회한 결과에는
사용자가 만든 모든 객체정보들을 알 수 있어요.
이중에는 테이블명도 있고
뷰도 있고 제약들도 있습니다.
------------------------------------------------
user_tables 는
데이터 사전중에
사용자가 만든 테이블에 대한 정보를 갖고 있는 데이터 사전입니다.
desc user_tables;
==> user_tables의 구조를 확인합니다.
SQL> desc user_tables;
이름 널? 유형
----------------------------------------- -------- ----------------------------
TABLE_NAME NOT NULL VARCHAR2(128)
TABLESPACE_NAME VARCHAR2(30)
CLUSTER_NAME VARCHAR2(128)
IOT_NAME VARCHAR2(128)
STATUS VARCHAR2(8)
PCT_FREE NUMBER
PCT_USED NUMBER
==> TABLE_NAME 을 조회 해 봅니다.
select table_name
from user_tables;
TABLE_NAME
----------
BOARD
NEWBOOK
TEST
STUDENT
GOODS
BOOK
CUSTOMER
ORDERS
DEPT
EMP
DETAIL
PRODUECT
극장
상영관
고객
예약
16 행이 선택되었습니다.
------------------------------------------------------
이번에는 index에 대해서 알아보겠습니다.
Index(인덱스)
==> 조건식에 자주 사용되는 컬럼에 대하여
미리 색인표를 만들어 두는 것을 말합니다.
인덱스를 만들어 두면 검색시에 빠른 성능을 기대할 수 있어요.
어떤 책이 한 권 있다고 가정합시다.
그런데 그 책이 10페이지 안돼요.
이런경우에는 굳이 색인표를 만들 필요가 없어요.
이경우에 색인표를 만들거나 안만들거나 성능차이를 기대할 수 없어요.
책이 굉장이 두꺼워요. 1000페이지 600페이지 정도 된다면
색인표가 있으면 빠르게 찾는 것을 도움 받을 수 있어요.
이것 처럼
데이터 양(레코드 수)이 많을때에
검색(조건식)에 빈번히 사용하는 컬럼에 대하여
"인덱스"를 만들어 두면 검색시에 성능향상을 기대할 수 있어요.
데이터 양이 적으면
"인덱스"가 있느나 없으나 성능효과를 체감하기는 어려워요.
엄~~~~청 많을때에
인덱스가 있을때와 없을때 조회의 성능을 체감할 수 있어요.
또,
만약에 책을 만들어 두고
책 맨뒤에 "색인표"까지 만들어 두었는데
책 내용이 빈번히 바뀐다면
"색인표"는 의미가 없어지고
오히려 찾기가 어려워요!
마찬가지로
데이터의 수정이 빈번한 칼럼
"인덱스"를 만들어 두면
오히려 "성능저하"의 요인이 될 수 있습니다.
<< 인덱스를 만드는 방법 >>
create index 인덱스이름 on 테이블이름(칼럼이름[들]);
select * from book where bookname = '재미있는 자바';
연습) 도서명에 인덱스를 만들어 봅시다.
create index idx_book on book(bookname);
==> 데이터 양이 많을 때에
인덱스가 있을때와 없을때의
조회의 성능 차이를 기대할 수 있습니다.
지금의 데이터 양으로는
조회의 성능 차이가 없습니다.
14번의 도서명을 '재미있는 오라클'로 수정 해 봅니다.
update book set bookname = '재미있는 오라클'
where bookid = 14;
위와 같이
인덱스를 만들어 둔 칼럼 bookname에 대하여
자료수정, 추가, 삭제가 빈번히
일어났다면 오히려 성능 저하의 요인이 될 수 있어요.
==> 인덱스를 재구성 해야 합니다.
<< 인덱스 재 구성 하기 >>
alter index 인덱스이름 rebuild;
alter index idx_book rebuild;
SQL> alter index idx_book rebuild;
인덱스가 변경되었습니다.
-----------------------------------------------------------
** 인덱스가 효과를 발휘하려면
데이터 수정이 빈번하지 않아야 하고
또, 인덱스를 설정한 칼럼의 같은 값의 종류가
많지 않아야 의미가 있어요.
100만건의 데이터 중에 "주소"칼럼의 값의 종류가
"서울", "울산", "광주" 세가지 밖에 없어요.
이럴때에는 인덱스가 오히려 성능 저하의 요인이 됩니다.
이때에는 인덱스를 삭제하는 것이 좋아요.
<< 인덱스 삭제하기 >>
drop index 인덱스이름;
drop index idx_book;
----------------------------------------------------
지금 부터 PL/SQL에 대하여 학습하겠습니다.
오라클 안에서도 프로그램을 만들 수 있어요!
오라클 전용 프로그래밍 언어
PL/SQL입니다.
(Procedural Language Structured Query Language)
--------------------------------------------------
PL/SQL로 만들 수 있는 것
- procedure ==> 자바의 메소드와 유사
- function ==> select절에 사용할 수 있어요.
- trigger ==> 이벤트(insert, update, delete)
가 발생하였을때 연쇄하여 동작
=====================================================
<< 프로시저 만들기 >>
create or replace procedure 프로시저이름(변수명 모드 자료형,..)
as
지역변수(들)
begin
프로시저가 해야할 sql명령어(들)
end;
/
모드의 종류
in 입력용, 프로시저가 일을 하기 위해
값을 전달 받기 위한 모드
out 출력용, 프로시저가 일을 한 결과를
돌려 주기 위한 모드
------------------------------------------------------
연습) 도서번호, 도서명, 출판사, 가격을 매개변수로 전달받아
도서를 추가하는 프로시저를 만들고 프로시저를 호출하여 insert를 수행 해
봅니다.
create or replace procedure insertBook(
myBookID in book.bookid%TYPE,
myBookName in book.bookname%TYPE,
myPublisher in book.publisher%TYPE,
myPrice in book.price%TYPE
)
as
begin
insert into book(bookid,bookname,publisher,price) values(myBookID,myBookName,myPublisher,myPrice);
end;
/
경고: 컴파일 오류와 함께 프로시저가 생성되었습니다.
<< 오류의 확인 >>
show errors;
<< 프로시저의 호출 >>
exec 프로시저명(값1, 값2, ..)
연습) 프로시저를 호출하여 새로운 도서를 추가 해 봅니다.
도서번호, 도서명, 출판사, 가격
exec insertBook(16,'신나는 오라클', '코스타미디어',20000);
SQL> exec insertBook(16,'신나는 오라클', '코스타미디어',20000);
PL/SQL 처리가 정상적으로 완료되었습니다.
연습) 도서번호와 가격을 매개변수로 전달받아
해당도서의 가격을 수정하는 프로시저를 만들고 호출 해 봅니다.
create or replace procedure updatebook(
myBookID book.bookid%TYPE,
myPrice book.price%TYPE
)
as
begin
update book set price = myPrice where bookid = myBookID;
end;
/
exec updatebook(15,30000);
연습) 도서번호를 매개변수로 전달받아
해당 도서를 삭제하는 프로시저를 만들고 호출 해 봅니다.
create or replace procedure deleteBook(
myBookID in book.bookid%TYPE
)
as
begin
delete book where bookid = myBookID;
end;
/
SQL> exec deleteBook(16);
PL/SQL 처리가 정상적으로 완료되었습니다.
----------------------------------------------------
<< PL/SQL에서 선택문 사용하기 >>
==> 조건에 따라 실행할 sql문을 선택하도록 할 수 있어요!
<< 선택문의 형식 >>
if 조건식 then
참일때 실행시킬 SQL
else
거짓일때 실행실 SQL
end if;
연습) 도서번호,도서명,출판사,가격을 매개변수로 전달받아
해당 도서가 이미 있다면 도서의 가격을 수정하고
그렇지 않다면 도서를 추가하는 프로시저를 생성하고
호출 해 봅니다.
create or replace procedure BookInsertOrUpdate(
myBookID book.bookid%TYPE,
myBookName book.bookname%TYPE,
myPublisher book.publisher%TYPE,
myPrice book.price%TYPE
)
as
mycount number;
begin
select count(*) into mycount from book where bookid = myBookID;
if mycount = 0 then
insert into book(bookid,bookname,publisher,price)
values(myBookID,myBookName,myPublisher,myPrice);
else
update book set price = myPrice where bookid = myBookID;
end if;
end;
/
도서번호,도서명,출판사,가격
exec BookInsertOrUpdate(16, '신나는 오라클','코스타미디어',30000);
exec BookInsertOrUpdate(16, '신나는 오라클','코스타미디어',35000);
------------------------------------------------------------------------
<< 반환 값이 있는 프로시저 만들기 >>
create or replace procedure 프로시저이름(
매개변수 in 자료형,
매개변수1 out 자료형,
매개변수2 out 자료형,
..
);
as
begin
select 칼럼1,칼럼2,.. into 매개변수1,매개변수2.. from ~~
end;
/
========================================================
도서의 평균 가격을 반환하는 프로시저를 만들어 봅니다.
create or replace procedure getAvgPrice(
avgPrice out number
)
as
begin
select avg(price) into avgPrice from book;
end;
/
<< 반환값이 있는 프로시저 호출하기 >>
변수를 선언하고 프로시저를 호출하고 반환값을 확인(출력)하기 위한 프로그램이 필요해요.
PL/SQL구문이 필요해요.
set serveroutput on; <--- 화면에 결과를 출력하기 위해 필요한 설정
<< pl/sql의 기본 구조 >>
declare
변수명 자료형;
begin
프로시저호출(변수명); <-- 프로시저에서 전달하는 변수에 값을 담아줌.
dbms.output.put_line(변수명) <-- 콘솔에 출력하는 명령
end;
------------------------------------------------
연습) 평균도서가격을 반환하는 프로시저를 호출 해 봅시다.
set serveroutput on;
declare
result number;
begin
getAvgPrice(result);
dbms_output.put_line('책값 평균' || result);
end;
/
SQL> declare
2 result number;
3 begin
4 getAvgPrice(result);
5 dbms_output.put_line('책값 평균' || result);
6 end;
7 /
책값 평균18730.7692307692307692307692307692307692
PL/SQL 처리가 정상적으로 완료되었습니다.
---------------------------------------------------------------
연습) 고객번호를 매개변수로 전달받아
해당 고객의 총구매건수와 총구매금액을 반환하는 프로시저를 만들고
호출 해 봅니다.
select count(*), sum(saleprice) from orders where custid=1;
create or replace procedure getCustomer(
myCustID in orders.custid%TYPE,
myCnt out number,
mySum out number
)
as
begin
select count(*), sum(saleprice) into myCnt, mySum from orders where custid=myCustID;
end;
/
declare
c number;
s number;
begin
getCustomer(1,c,s);
dbms_output.put_line('총구매건수:' || c);
dbms_output.put_line('총구매금액:' || s);
end;
/
-------------------------------------------------------------------
<< cursor의 사용 >>
==> 프로시저 안에서 select 한 결과가 여러건 일 때 사용합니다.
<< cursor를 사용하는 방법 >>
create or replace procedure 프로시저이름
(
매개변수(들)
)
as
지역변수(들)
cursor 커서이름 is select ~~
begin
open 커서이름; <--- 이때 sql이 동작합니다.
loop <--- 반복문 시작
fetch 커서이름 into 변수1, 변수2, .. <-- select한 칼럼의 값을 변수에 저장.
exit when 커서이름%NOTFOUND; <-- 더이상 레코드가 없으면 반복문 탈출
end loop; <--- 반복문 끝
close 커서이름;
end;
/
연습) 고객번호를 매개변수로 전달받아
해당고객이 구매한 모든 도서명을 출력하는
프로시저를 만들고 호출 해 봅니다.
select bookname from book b, orders o
where b.bookid = o.bookid and
custid = 1;
create or replace procedure orderBook2(
myCustID orders.custid%TYPE
)
as
myBookName varchar2(30);
cursor c is select distinct bookname from book b, orders o
where b.bookid = o.bookid and
custid = myCustID;
begin
open c;
loop
fetch c into myBookName;
dbms_output.put_line(myBookName);
exit when c%NOTFOUND;
end loop;
close c;
end;
/
SQL> exec orderBook2(1)
축구의 역사
축구아는 여자
축구의 이해
재미있는 오라클
신나는 자바
신나는 자바 <---- procedure로 distinct가 적용되지 않아요.
프로그램을 중복을 제거해야 합니다.
PL/SQL 처리가 정상적으로 완료되었습니다.
연습) 모든 주문에 대하여 총이익금을 계산하여 출력하는
프로시저를 만들고 호출 해 봅니다.
주문가격이 30000원 이상이면 이익금은 10%
그렇지 않으면 5%입니다.
create or replace procedure printAllProfit
as
total number;
price number;
profit number;
cursor c is select saleprice from orders;
begin
total := 0;
open c;
loop
fetch c into price;
if price >= 30000 then
profit := price * 0.1;
else
profit := price * 0.05;
end if;
total := total + profit;
exit when c%NOTFOUND;
end loop;
close c;
dbms_output.put_line('총 이익금:' || total);
end;
/
SQL> exec printAllProfit();
총 이익금:50100
================================================================
<< trigger >>
어떠한 테이블에 insert, update, delete이 일어났을때에
연쇄하여 자동으로 동작시키고자 할 sql문장이 있다면
트리거를 이용합니다.
<< 트리거 만들기 >>
create or replace trigger 트리거이름
시점 이벤트종류
on 테이블명 for each row
declare
begin
end;
/
==> 시점에는 before, after가 올 수 있어요.
==> 이벤트에는 insert, update, delete이 올 수 있어요
==> 트리에서 사용할 수 있는 키워드
:new ==> insert,update가 된 새로운 행을 의미하는 변수입니다.
:old ==> delete,update가 되기전 과정의 행을 의미하는 변수입니다.
----------------------------------------------------------
** 실습을 위하여 dept 테이블을 복사하여 dept_back테이블을 만들어 봅시다.
create table dept_back as select * from dept;
연습) dept에 새로운 레코드가 추가 되면 그 동일한 레코드를
dept_back에 추가하는 트리거를 만들어 봅시다.
create or replace trigger trg_insert_dept
after insert
on dept for each row
declare
begin
insert into dept_back values( :new.dno, :new.dname, :new.dloc );
end;
/
연습) dept에 레코드가 수정되면
자동으로 dept_back에도 수정이 되도록
트리거를 만들고 확인 해 봅니다.
create or replace trigger trg_update_dept
after update
on dept for each row
declare
begin
update dept_back set dname = :new.dname, dloc = :new.dloc where dno = :new.dno;
end;
/
SQL> update dept set dloc = '제주' where dname like '개발%';
4 행이 업데이트되었습니다.
SQL> select * from dept;
DNO DNAME DLOC
----- ---------------------------------------- ----------------------------------------
10 기획팀 종각
20 영업팀 종각
30 개발1팀 제주
40 개발2팀 제주
50 개발3팀 제주
60 개발4팀 제주
6 행이 선택되었습니다.
SQL> select * from dept_back;
DNO DNAME DLOC
----- ---------------------------------------- ----------------------------------------
10 기획팀 종각
20 영업팀 종각
30 개발1팀 제주
40 개발2팀 제주
50 개발3팀 제주
60 개발4팀 제주
6 행이 선택되었습니다.
SQL>
rollback;
연습) dept에 레코드가 삭제되면 동일한 부서번호의 레코드를
dept_back에서도 삭제되도록 트리거를 만들고 잘 동작하는지 확인합니다.
create or replace trigger trg_delete_dept
after delete
on dept for each row
declare
begin
delete dept_back where dno = :old.dno;
end;
/
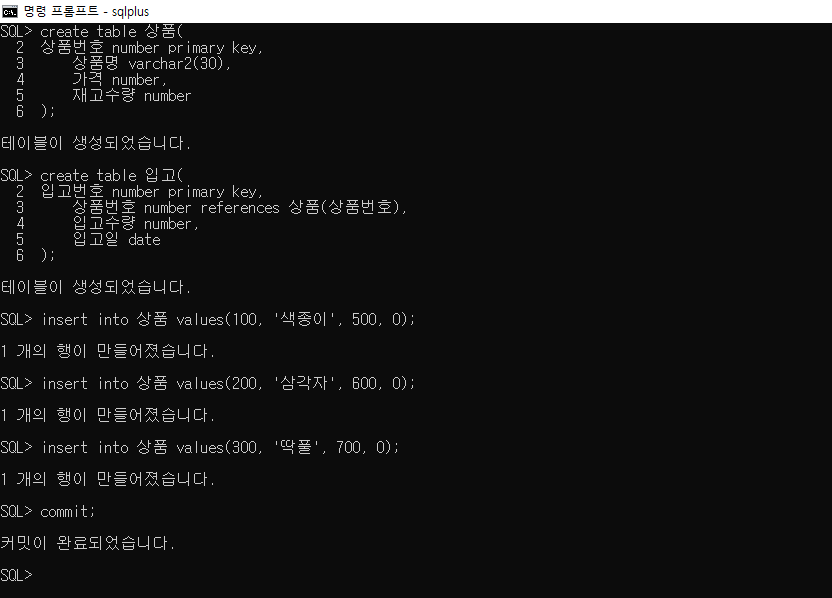
create table 상품(
상품번호 number primary key,
상품명 varchar2(30),
가격 number,
재고수량 number
);
create table 입고(
입고번호 number primary key,
상품번호 number references 상품(상품번호),
입고수량 number,
입고일 date
);
insert into 상품 values(100, '색종이', 500,0);
insert into 상품 values(200, '삼각자', 700,0);
insert into 상품 values(300, '딱풀', 600,0);
column 상품번호 format 9999;
column 가격 format 9,999,999;
column 재고수량 format 9999;
column 입고번호 format 9999;
column 입고수량 format 9999;
column 상품명 format a10;
column 입고일 format a15;
연습) "입고"테이블에 레코드가 추가되면
상품테이블에 해당상품의 재고수량을 입고수량만큼
증가시키는 트리거를 만들고 잘 동작하는지 확인합니다.
create or replace trigger trg_insert_입고
after insert
on 입고 for each row
declare
begin
update 상품 set 재고수량 = 재고수량 + :new.입고수량
where 상품번호 = :new.상품번호;
end;
/
연습) 입고테이블에 레코드가 삭제되면
해당상품의 재고수량을 감소시키는 트리거를 만들고
결과를 확인 해 봅니다.
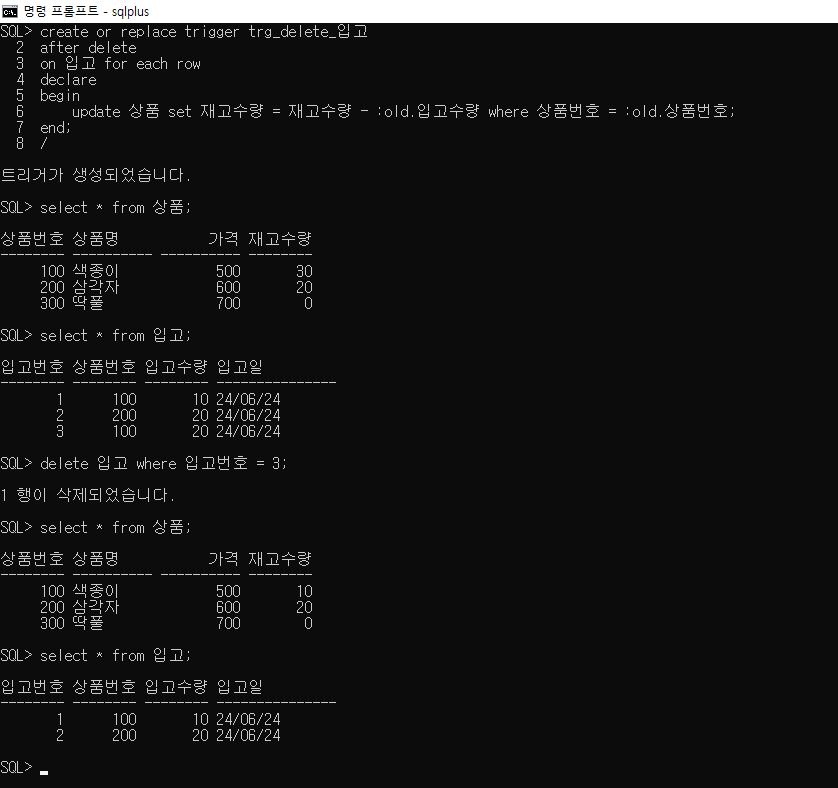
create or replace trigger trg_delete_입고
after delete
on 입고 for each row
declare
begin
update 상품 set 재고수량 = 재고수량 - :old.입고수량
where 상품번호 = :old.상품번호;
end;
/
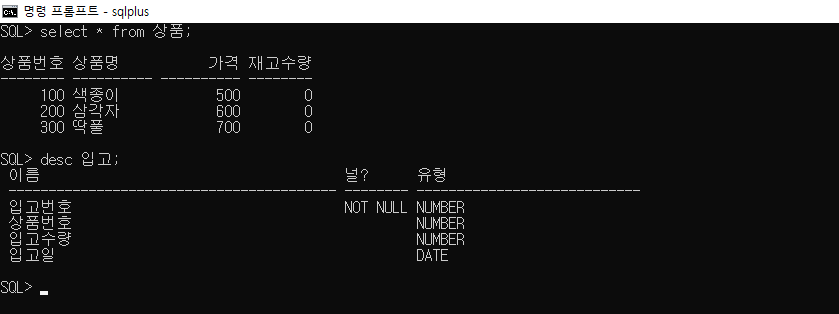
SQL> select * from 상품;
상품번호 상품명 가격 재고수량
-------- ---------- ---------- --------
100 색종이 500 30
200 삼각자 700 20
300 딱풀 600 0
SQL> select * from 입고;
입고번호 상품번호 입고수량 입고일
-------- -------- -------- ---------------
1 100 10 24/06/24
2 200 20 24/06/24
3 100 20 24/06/24
SQL> delete 입고 where 입고번호 = 3;
1 행이 삭제되었습니다.
SQL> commit;
커밋이 완료되었습니다.
SQL> select * from 상품;
상품번호 상품명 가격 재고수량
-------- ---------- ---------- --------
100 색종이 500 10
200 삼각자 700 20
300 딱풀 600 0
SQL> select * from 입고;
입고번호 상품번호 입고수량 입고일
-------- -------- -------- ---------------
1 100 10 24/06/24
2 200 20 24/06/24
SQL>
14:00 ~
대입 연산자 > :=
total := 0;
if () then
else
end if;
dept;
dept_back;
~ 본체바꿈 이슈로 데이터베이스 null ~
create table 상품(
상품번호 number primary key,
상품명 varchar2(30),
가격 number,
재고수량 number
);
insert into 상품 values(100, '색종이', 500, 0);
insert into 상품 values(200, '삼각자', 600, 0);
insert into 상품 values(300, '딱풀', 700, 0);create table 입고(
입고번호 number primary key,
상품번호 number references 상품(상품번호),
입고수량 number,
입고일 date
);
column 상품번호 format 9999;
column 가격 format 9,999,999;
column 재고수량 format 9999;
column 입고번호 format 9999;
column 입고수량 format 9999;
column 상품명 format a10;
column 입고일 format a15;
연습) "입고" 테이블에 레코드가 추가되면 상품테이블에 해당 상품의 재고수량을 입고수량만큼 증가시키는
트리거를 만들고 잘 동작하는지 확인합니다
create or replace trigger trg_insert_입고
after insert
on 입고 for each row
declare
begin
update 상품 set 재고수량 = 재고수량 + :new.입고수량 where 상품번호 = :new.상품번호;
end;
/
insert into 입고 values(1, 100, 10, sysdate);
insert into 입고 values(2, 200, 20, sysdate);
insert into 입고 values(3, 100, 20, sysdate);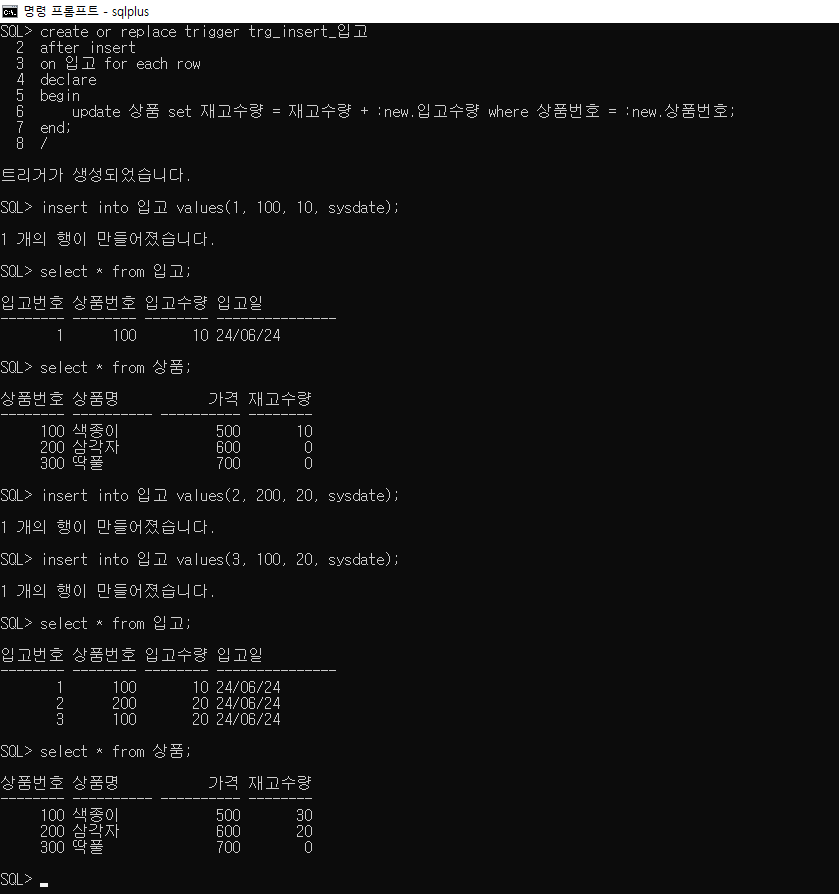
연습) 입고 테이블에 레코드가 삭제되면 해당 상품의 재고수량을 감소시키는 트리거를 만들고
결과를 확인 해 봅니다
create or replace trigger trg_delete_입고
after delete
on 입고 for each row
declare
begin
update 상품 set 재고수량 = 재고수량 - :old.입고수량 where 상품번호 = :old.상품번호;
end;
/
delete 입고 where 입고번호 = 3;show errors;
-- update 하기
insert into 입고 values(3, 200, 10, sysdate);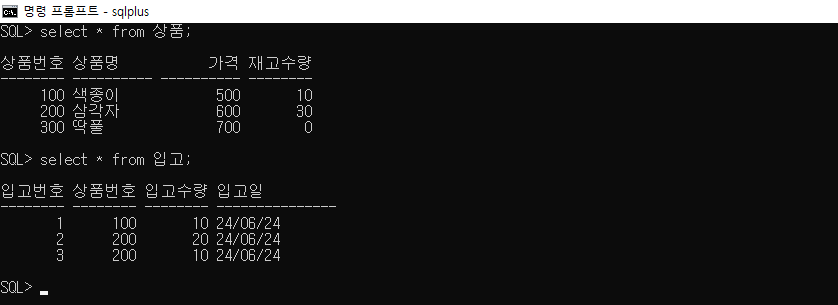
연습) 입고 테이블에 수정이되면 수정 된 입고수량만큼 상품테이블의 재고수량도 수정이 되도록
트리거를 만들고 확인 해 봅니다
create or replace trigger trg_update_입고
after update
on 입고 for each row
declare
begin
update 상품 set 재고수량 = 재고수량 - (:old.입고수량 - :new.입고수량)
where 상품번호 = :new.상품번호;
end;
/
update 입고 set 입고수량 = 5 where 입고번호 = 3;update 입고 set 입고수량 = 5 where 입고번호 = 3; --> :new
3 200 10 24/06/24 --> :old
3 200 5 24/06/24 --> :new
재고수량 - (:old.입고수량 - :new.입고수량)
update 입고 set 입고수량 = 20 where 입고번호 = 3; --> :new
3 200 10 24/06/24 --> :old
3 200 10 24/06/24 --> :new
update 상품 set 재고수량 = 재고수량 - (:old.입고수량 - :new.입고수량)
where 상품번호 = :new.상품번호; // :new :old 관계없음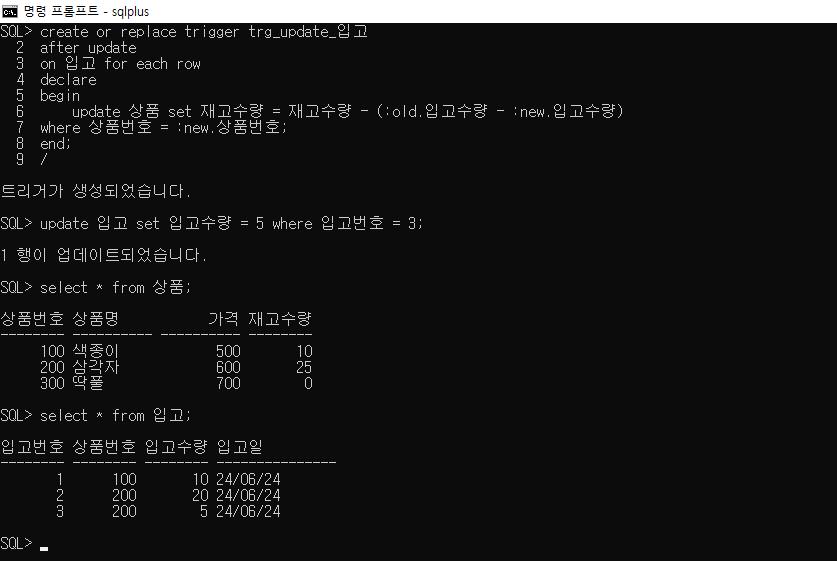
insert into 입고 values(4, 100, 10, sysdate);
- 데이터베이스 평가
- 오늘 학습한 내용에 대하여 요약, 정리하고 궁금한 점 질문합니다
- 요약 및 정리가 끝나면 팀별로 프로젝트 관련 회의를 진행합니다
'📖' 카테고리의 다른 글
| day 0625 (0) | 2024.06.25 |
|---|---|
| day 0619 (0) | 2024.06.19 |
| day 0618 데이터베이스(4) (0) | 2024.06.18 |
| day 0617 데이터베이스(3) (0) | 2024.06.17 |
| day 0614 데이터베이스 모델링(2) (0) | 2024.06.14 |
'📖' Related Articles
more


