
기록
day 0611 데이터베이스(1) 본문
14:00 ~
급성 위장염 이슈로 ~~~ 집에서 소리 없이 강의 화면만 보기 ㅠ
학원 못 나갔는데 선생님이 사장시켜주셨다 ㅋㅋ ㅋㅋㅋ

1004 진구들이 보내준 필기 바탕으로 6월 11일 기록하기✨
고마워 진구들아 ~ !~!
insert into book values(11, '신나는 축구', 15000, '코스타미디어');
insert into book values(12, '즐거운 축구', 25000,'코스타미디어');
<< like 연산자 >>
문자열의 어떠한 패턴을 만족하는 데이터를 조회할 때 사용
% : 모르는(아무글자) 0개이상의 글자
_ : 모르는(아무글자) 1개의 글자
도서명에 '축구'를 포함하고 있는 모든 도서를 출력
select * from book where bookname like '%축구%';
도서명이 '축구'로 시작하는 도서의 정보를 출력
select * from book where bookname like '%축구%';
도서명이 '축구'로 끝나는 도서의 정보를 출력
select * from book where bookname '%축구';
insert into customer values(6, '김동규', '대한민국 서울', '010-6666-6666');
insert into customer values(7, '김철', '대한민국 대전', '010-7777-7777');
insert into customer values(8, '김민', '대한민국 전주', '010-8888-8888');
성씨가 '김'씨인 모든 고객의 정보를 출력
select name from customer where name like '김%';
성씨가 '김'씨이고 성을 포함하여 이름이 2글자인 고객의 정보를 출력
select name from customer where name like '김_';
성씨가 '김'씨이고 성을 포함하여 이름이 3글자인 고객의 정보를 출력
select name from customer where name like '김__';
성이 '김'씨이고, '서울'에 거주하는 고객의 정보를 출력
select name from customer where name like '김%' and address like '%서울%';
-- 레코드를 추가하면 순서는 유지 되지 않는다
-- 조회할 때에 순서를 정해 줄 수 있다
<< 데이터 조회하기 >>
select 칼럼명
from 테이블명
[where 조건절]
[order by 칼럼명]
오름차순 : order by 칼럼명 asc;
내림차순 : order by 칼럼명 desc;
모든 도서의 정보를 가격순으로 정렬하여 출력
select * from book order by price;
축구관련 도서의 도서명, 가격, 출판사명을 가격이 높은순으로 출력
select bookname, price, publisher from book where bookname like '%축구%' order by price desc;
도서명의 두번째 글자가 '구' 이고 가격이 5000원과 50000원 사이인 도서의 도서명, 가격, 출판사명을 출력
(출판사 순으로 정렬하고 출판사가 동일할 때에는 가격순으로 출력)
select bookname, price, publisher
from book
where bookname like '_구%'
and price between 5000 and 50000
order by publisher, price
<< 데이터베이스 명령어 종류 >>
DDL : 데이터 정의어 (CREATE, DROP, ALTER)
DML : 데이터 조작어 (INSERT, UPDATE, DELETE, SELECT)
DCL : 데이터 제어어 (GRANT, REVOKE)
<< 데이터 조회하기 >>
select 칼럼명 from 테이블명 [where 조건절] [order by asc/desc]
전화번호가 '010-6666-6666' 인 고객의 이름과 주소를 출력
select name, address from customer where phone='010-6666-6666';
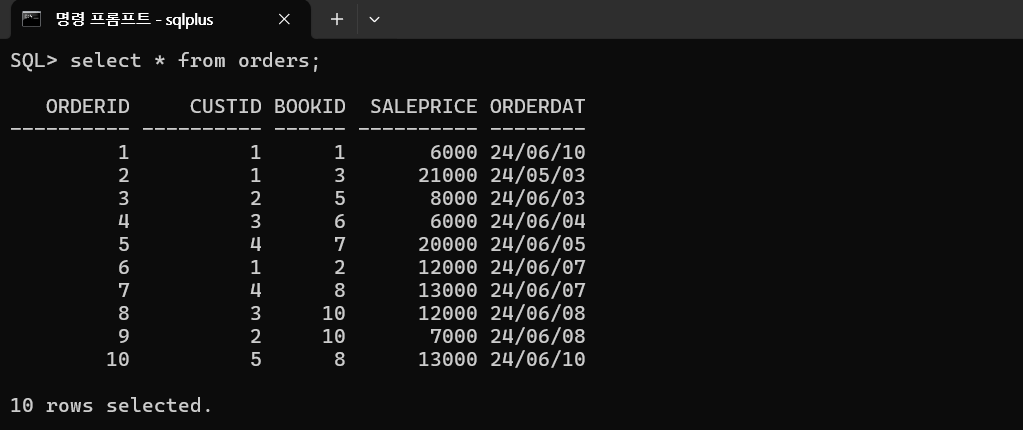
고객번호가 1번인 고객의 주문내역을 출력
select * from orders where custid = 1;
도서번호 10번이거나 8번이거나 3번인 도서의 주문내역을 최근의 주문일 순서대로 출력
select * from orders where bookid in (3,8,10);
'야구'관련 도서의 도서명, 가격, 출판사를 출력, 가격이 높은순으로 출력하고 가격이 동일할 때에는 도서명순으로 출력
select bookname, price, publisher from book
where bookname like '%야구%'
order by price desc, bookname asc;
'2024/06/01' 과 '2024/06/10' 사이에 판매된 판매가격이 20000원 이상인 판매내역을 출력
(최근의 판매내역부터 출력, 판매일이 동일할 때에는 판매가격이 높은순으로 출력)
select * from orders
where orderdate between '2024/06/01' and '2024/06/10'
and saleprice>=20000
order by orderdate desc, saleprice desc;
10번 도서를 구매한 고객의 이름을 출력
-- 고객의 이름은 customer 테이블에 있다
-- 10번 도서의 판매내역은 orders 테이블에 있다
위와 같이 조회하고자하는 칼럼이나 조건식이
두개이상의 테이블에 있을 때 "조인"을 이용한다
select 칼럼명
from 테이블1, 테이블2
where 조인식;
조인식
: 두 테이블의 공통으로 들어가는 칼럼을 써준다
10번 도서를 구매한 고객의 이름을 출력
select name
from customer, orders
where customer.custid = orders.custid
and bookid = 10;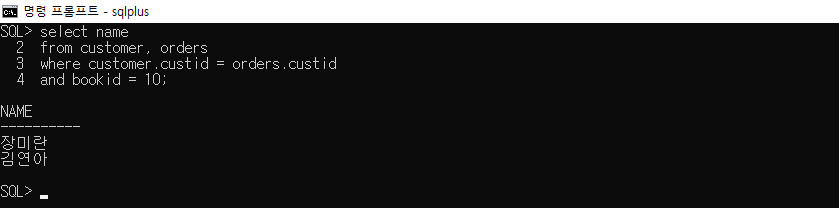
1번 고객이 구매한 도서명을 검색
select bookname
from orders, book
where orders.bookid = book.bookid
and custid=1;
<< 테이블에 별칭을 줄 수 있다 >>
select bookname
from book b, orders o
where b.bookid = o.bookid and custid = 1;
select bookid, bookname, price, saleprice, orderdate, publisher
bookid는 book 테이블에도 있고 orders 테이블에도 있기때문에 둘 중 아무 테이블에 지정
=> select b.bookid, bookname, price, saleprice, orderdate, publisher
=> select o.bookid, bookname, price, saleprice, orderdate, publisher
1번 고객이 주문한 도서번호, 도서명, 도서가격, 구매가격, 구매일, 출판사명을 출력
select b.bookid, b.bookname, b.price, o.saleprice, o.orderdate, b.publisher
from book b, orders o
where b.bookid = o.bookid
and custid = 1;
'장미란'고객이 주문한 내역에 대하여 고객번호, 주소, 전화, 도서번호, 도서명, 구매일, 구매가격을 출력
(최근의 구매일 부터 출력)
select c.custid, c.address, c.phone, b.bookid, b.bookname, o.orderdate, o.saleprice
from orders o, book b, customer c
where b.bookid = o.bookid and c.custid = o.custid
and c.name = '장미란'
order by o.orderdate desc;
'이상미디어'나 '대한미디어'의 '축구' 나 '야구' 관련 도서중에가격이 10000원 이상인
도서를 구매한 고객의 고객번호, 고객이름, 도서번호, 도서명, 구매일을 출력하시오
(최근의 구매일 순으로 출력하고, 동일할 때에는 도서번호순으로 출력)
select c.custid, c.name, b.bookid, b.bookname
from customer c, book b, orders o
where c.custid = o.custid and b.bookid = o.bookid
and b.publisher in ('이상미디어', '대한미디어')
and (b.bookname like '%축구%' or b.bookname like '%야구%')
and b.price >= 10000
order by o.orderdate desc, o.bookid asc;
<< 새로운 테이블 만들기 >>
부서(부서번호, 부서명, 부서위치)
사원(사원번호, 사원명, 직책, 입사일, 급여, 부서번호, 관리자번호)
dept(dno, dname, dloc)
emp(eno, ename, job, hiredate, salary, dno, mgr)
create table dept(
dno number primary key,
dname varchar2(20),
dloc varchar2(20)
);
create table emp(
eno number primary key,
ename varchar2(20),
job varchar2(20),
hiredate date,
salary number,
dno number references dept(dno),
mgr number
);
insert into dept values(10, '기획팀', '종각');
insert into dept values(20, '영업팀', '종각');
insert into dept values(30, '개발1팀', '판교');
insert into dept values(40, '개발2팀', '가산');
insert into dept values(50, '개발3팀', '가산');
사장 : 나사장 ( 기획 )
과장 대리 사원 사원
기획 이과장, 박대리, 임사원, 홍사원
영업 최과장, 유대리, 유사원, 박사원
개발1 박과장, 김대리, 이사원, 조사원
개발2 강과장, 장대리, 공사원, 최사원
insert into emp values(1000, '나사장', '사장', '2010/01/03', 1000, 10, null);
insert into emp values(1001, '이과장', '과장', '2012/08/27', 600, 10, 1000);
insert into emp values(1002 , '박대리' , '대리' , '2014/07/28', 400, 10, 1001) ;
insert into emp values(1003, '임사원', '사원', '2023/10/10', 200, 10, 1002);
insert into emp values(1004, '홍사원', '사원', '2018/02/17', 200, 10, 1002);
insert into emp values(1005, '최과장', '과장', '2013/01/02', 500, 20, 1000);
insert into emp values(1006, '유대리', '대리', '2014/01/02', 400, 20, 1005);
insert into emp values(1007,'유사원','사원','2020/09/12',300,20,1006);
insert into emp values(1008,'박사원','사원','2020/09/12',300,20,1006);
insert into emp values(1009, '박과장', '과장', '2012/12/03', 500, 30, 1000);
insert into emp values(1010, '김대리', '대리', '2020/02/12', 600, 30, 1009);
insert into emp values(1011, '이사원', '사원', '2024/06/11', 100, 30, 1010);
insert into emp values(1012, '조사원', '사원', '2020/03/05', 400, 30, 1010);
insert into emp values(1013, '강과장', '과장', '2014/10/20', 600, 40, 1000);
insert into emp values(1014, '장대리', '대리', '2015/01/05', 500, 40, 1013);
insert into emp values(1015, '공사원', '사원', '2024/04/14', 400, 40, 1014);
insert into emp values(1016, '최사원', '사원', '2010/01/05', 700, 40, 1014);
ed ff
column eno Format 9999;
column ename Format a20;
column job Format a20;
column hiredate Format 999,999;
column dno Format 9999;
column mgr Format 9999;
@@ff
종각에 근무하는 직원들의 사원번호, 부서번호, 부서명, 직책, 입사일, 급여를 출력
(입사일 순으로 출력하고 동일할 때에는 사원번호 순으로 출력)
select e.eno, d.dno, d.dname, e.job, e.hiredate, e.salary
from emp e, dept d
where e.dno = d.dno
and d.dloc ='종각'
order by hiredate, e.eno;
개발팀에 근무하는 직원들의 부서번호, 부서명, 부서위치, 사원번호, 사원명, 입사일을 출력
(부서번호 순으로 출력하되, 동일한 경우에는 사원번호 순으로 출력)
select d.dno, d.dname, d.dloc, e.eno, e.ename, e.hiredate
from emp e, dept d
where e.dno = d.dno
and d.dname like '개발%'
order by d.dno, e.eno
직책이 '사원'이거나 '대리' 인 모든 직원들의 부서번호, 부서명, 직책, 입사일, 급여를 출력
(급여가 높은 순으로 출력하고 동일할 때에는 입사일 순으로 출력)
select d.dno, dname, job, hiredate, salary
from emp e, dept d
where e.dno = d.dno and
job in ('사원', '대리')
order by salary desc, hiredate;
'2020/01/01' 이전에 입사하고, 직책이 '사원'인 모든 직원들의 부서번호, 부서명, 사원명, 입사일을 출력
(입사일 순으로 출력하되 동일할 때에는 사원번호 순으로 출력)
select d.dno, dname, ename, hiredate
from emp e, dept d
where e.dno = d.dno
and hiredate<='2020/01/01'
and job = '사원'
order by hiredate, eno;
<< 집계함수 >>
레코드를 조회할 때에 레코드의 수나, 합, 평균등을 구하고자 할 때 사용하는 함수
count(칼럼명) : 레코드의 수
sum(칼럼명 ) : 총 합
avg(칼럼명) : 평균
max(칼럼명) : 최고값
min(칼럼명) : 최소값
모든 도서의 가격을 출력
select price from book;
모든 도서 가격의 총합을 출력
select sum(price) from book;
select bookname, sum(price) from book; <-- 불법
집계함수의 결과는 한건이기 때문에 같이 사용할 수 없다
모든 도서의 평균가격을 조회
select avg(price) from book;

도서의 최고가격을 조회
select max(price) from book;
도서의 최저가격을 조회
select min(price) from book;
모든 도서의 수를 조회
select count(price) from book;
select count(bookname) from book;
count(칼럼명) : 컬럼의 값이 null이 아닌 레코드의 수
count(*) : 모든 레코드의 수
'이상미디어'에서 출간하는 도서의 평균가격을 출력
select avg(price) from book where publisher='이상미디어';
'박지성' 고객이 주문한 총 건수와 총주문금액을 출력
select count(*) cnt, sum(saleprice) sum from orders where custid=1;
'축구'관련 도서의 총 도서의 수와 평균가격, 최고가격, 최저가격을 출력
select count(*) cnt, avg(price) avg, max(price) max, min(price) min
from book
where bookname like '%축구%';
'개발1팀'에 근무하는 총직원수와 평균급여를 출력
select count(e.dno) cnt, avg(salary) avg_salary
from emp e, dept d
where e.dno = d.dno
and dname='개발1팀';
'2024/06/01'과 '2024/06/10' 사이에 주문한 건수와 총 주문 금액을 출력
select count(*) cnt, sum(saleprice) sum
from orders
where orderdate between '2024/06/01' and '2024/06/10';
개발팀에 근무하는 직원들의 총 급여를 출력
select sum(salary) sum
from emp e, dept d
where e.dno = d.dno
and dname like '%개발%';
** 집계함수 정리
select price from book; <- 12개의 행
select bookname, price from book; <-- 12개의 행
select sum(price) from book; <-- 1개의 행
select bookname, sum(price) from book; <-- 말이 안 되는 소리
모든 도서의 평균금액은 한건이 나온다
만약 출판사별로 평균금액을 출력하고 싶으면 group by 를 사용하면 된다
이것은 출판사의 수 만큼 건수가 나온다
이럴때 사용하는 것이 group by 절 이다
select avg(price) from book; <-- 1건
select avg(price) from book group by publisher; <-- 출판사 만큼 행 출력
select publisher, avg(price) from book group by publisher;
-- 집계함수와 같이 사용할 수 있는 칼럼은 group by의 칼럼이다
<< 날짜 관련 클래스 >>
Date
Calendar
GregorianCalendar
Calendar의 후손이며 윤년 정보가 추가
Date
0 = Sunday
Calendar
SUNDAY 1
,,? ,,???,,,,,,,,,?????,,,,,,,,,,,,,
왜 이렇게 끝나는걸ㄲㅏ,,?,,,,,,,
'📖' 카테고리의 다른 글
| day 0613 데이터베이스 모델링(1) (1) | 2024.06.13 |
|---|---|
| day 0612 데이터베이스(2) (0) | 2024.06.12 |
| day 0610 상품_등록_수정_삭제_조회 (0) | 2024.06.10 |
| 데이터베이스 명령어 (1) | 2024.06.09 |
| day 0607 데이터베이스 연결 프로그래밍 수정_삭제 (1) | 2024.06.07 |



